Llama.cpp 使用帮助
- Llama.cpp: 用于运行语言聊天模型,可理解文本/音视频
如何使用
- 挂VPN,点击前往Github下载运行环境
- 从下载页面中选择适合自己的显卡或CPU的压缩包下载,其中
windows系统需要选择win字段的- 带
cuda字段的表示适用于N卡、英伟达显卡设备。如果 CUDA 版本跟你的系统安装不兼容,就会运行失败,可以点击对应下载链接后面的CUDA xx.x DLLs,然后解压到llama.cpp的.exe文件同目录即可 - 带
vulkan字段的表示适用于多种显卡设备,如果你明确知道自己是N卡或AMD显卡则选择cuda/rocm,不然就无脑下载vulkan - 其他的就是没有显卡加速的,只靠
CPU跑,相比有上述有显卡加速的会慢很多
- 带
- Llama.cpp 经常更新,会逐步添加新的显卡/CPU/AI模型的支持和优化,后续新模型无法运行时可尝试到
下载页面更新下载
- 下载模型,Llama.cpp需要GGUF格式的模型文件,国内建议复制想要的模型名称到魔搭社区搜索下载
- 这里以
Qwen3.5-9B为例,它需要主体模型+mmproj模型两部分,如果不需要AI支持理解图片,可以只下载主体模型 - 首先是
主体模型: 根据你的显卡的显存大小挑选模型,一般选显存容量减2G大小的模型,普遍规律是模型越大,效果越好,但越吃显存、运行越久,只要显存放得下,优先选尽可能大的追求质量,当然也可以选4bit量化之类的追求速度。我的话常用的就是4Bit量化,效果够用兼顾速度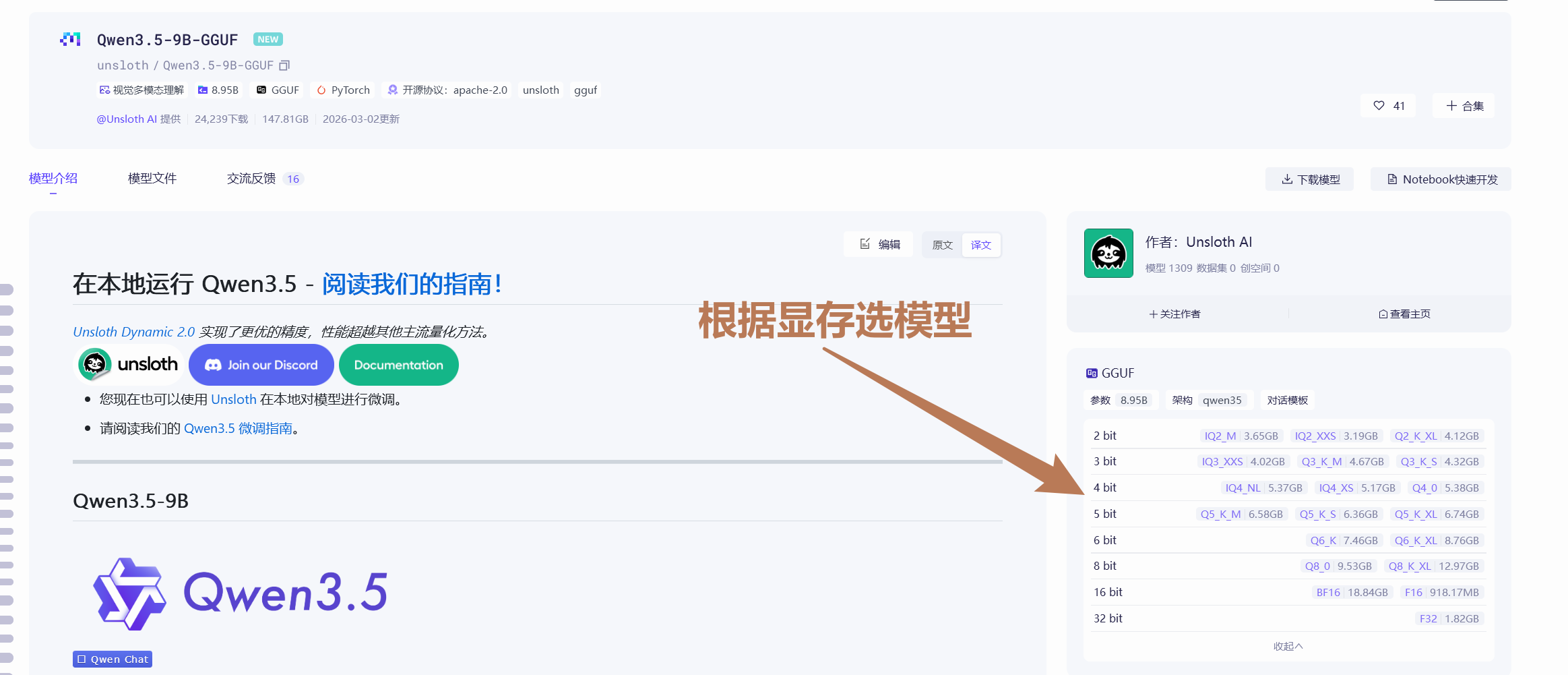
- 然后是
mmproj模型,建议选F16即可。mmproj模型跟主模型是对应的,不同模型比如qwen3.5-9B、qwen3.5-4B是不能混用的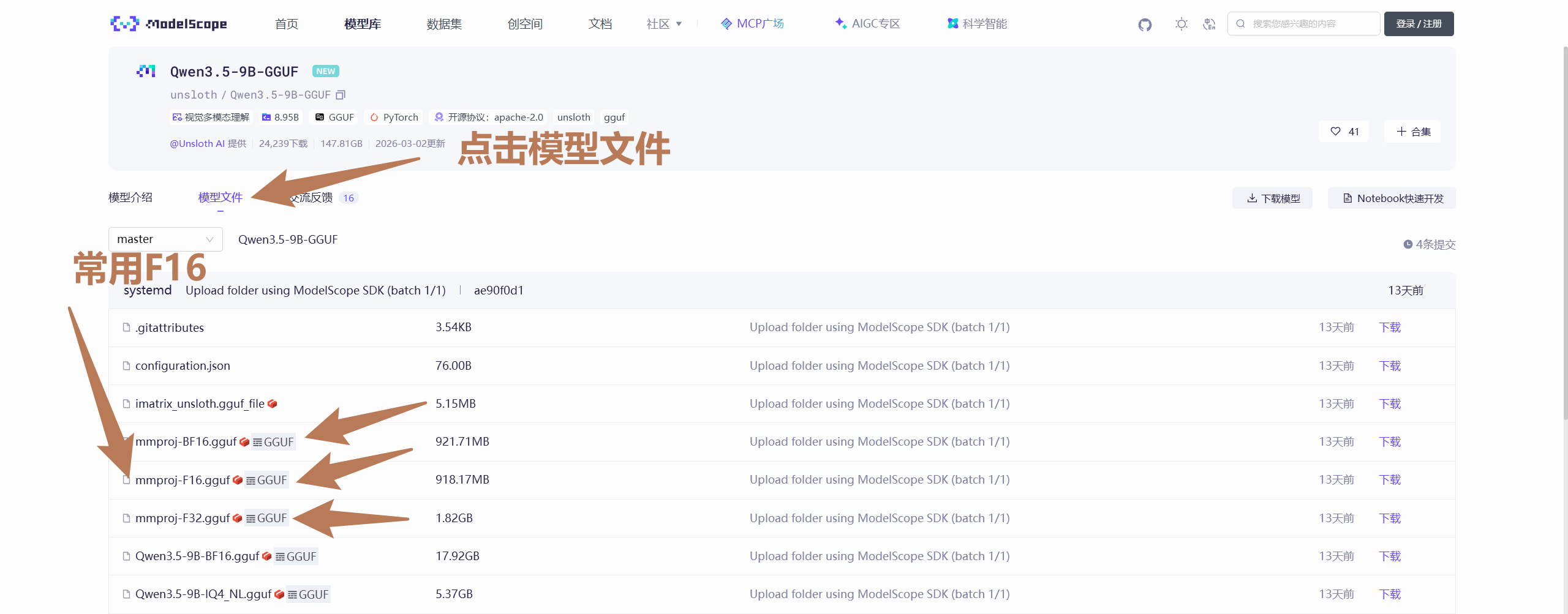
- 这里以
- 启动
流明运行模型,点击Llama.Cpp
- 填入文件路径即可:
Llama-Cpp目录,选择下载的 运行环境压缩包zip解压后的目录模型,选择qwen3.5-9B的主体模型路径mmproj多模态模型,可选,如果主体模型支持多模态,可添加选择对应的mmproj文件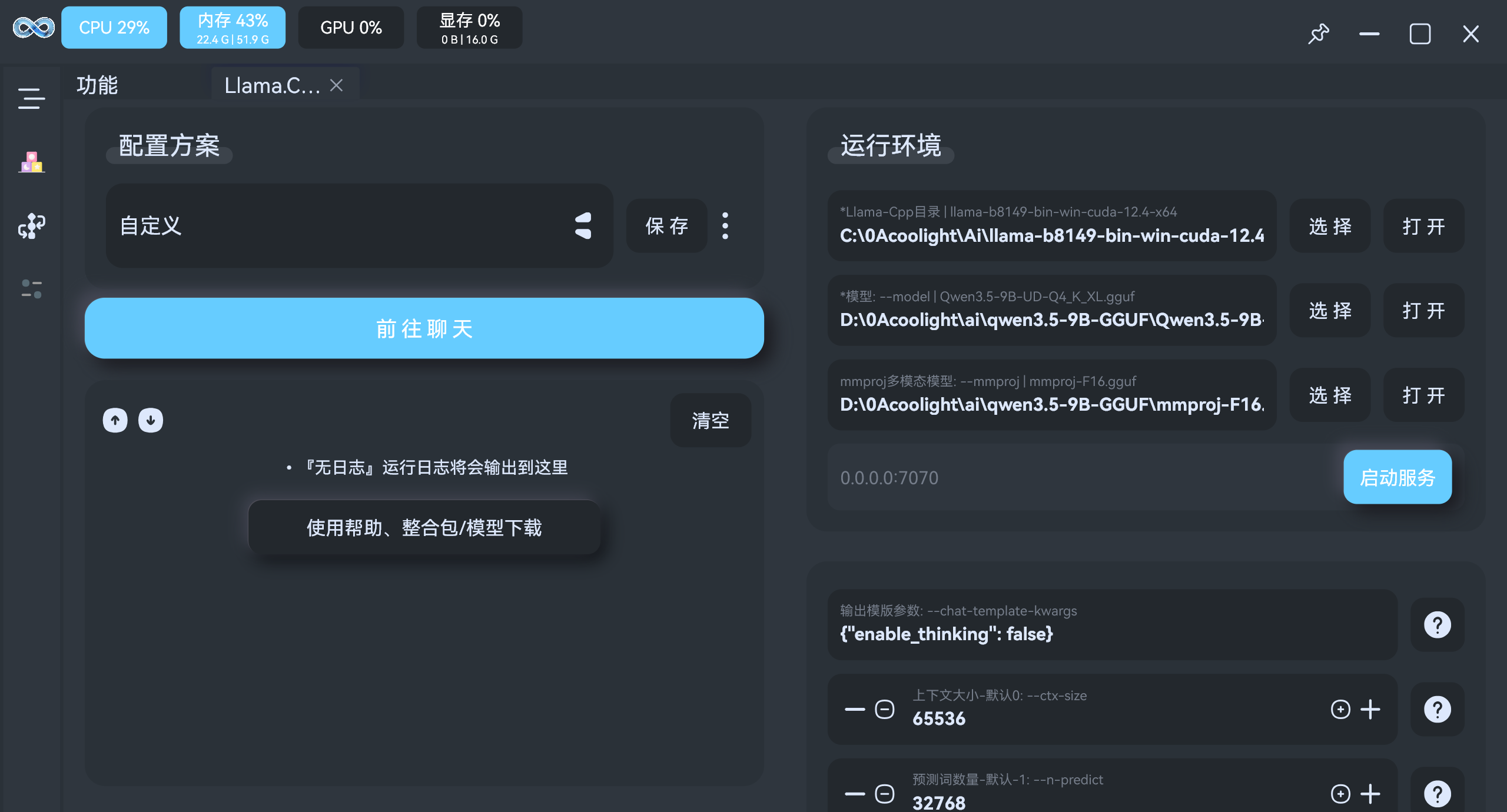
- 点击
启动服务 - 点击左边的
前往聊天即可
一键整合包
- 待发布
模型分享
- 模型仅供学习参考,投入使用时注意版权等问题。
- 很多他人分享的模型,不是我们训练的,模型质量和使用需留意其说明
- 魔搭社区